
Getting Started with Regexp, Simple and Clear 🤗
正則表達式(RegExp)是一種用於字符串搜索和替換的強大模式匹配語言。
通過定義特定的模式,它可以快速識別和提取文本數據中的關鍵信息,從而使數據處理變得更加高效和精確。
無論是數據清洗、日誌分析還是自然語言處理,正則表達式都是不可或缺的工具,幫助我們從繁雜的數據中提煉出有價值的信息。
什麼情況會使用到 RegExp|以車禍案件篩選為例
以 找到車禍案件為例,下面整理出 7 則在判決中會出現的片段,我們的任務是要找到車禍案件,
首先,我們先觀察一下是否有一定的規律可以進行歸納。
- 就本件車禍之發生自有過失,應就原告所受損害負賠償責任
- 足見被告對系爭車禍之發生,顯有過失
- 原告看到被告之機車停放於原告與陳明風同住之系爭住所外,原告早已耳聞兩人之間有曖昧關係
- 在前開191號房屋車庫門邊又拿了一條拉鐵門用的鐵條
- 隨即緊急煞車暫停於車道,致陳維德煞車不及,撞及上訴人車輛後端(下稱系爭事故)
- 被告由後方追撞原告之車輛,原告因而受有左側足部壓砸傷
- 甚至遭原告吐口水及左肩碰撞陸續之挑釁,…,該鐵條不但影響車輛進出 …
❓ 我們發現 …
- 不一定每篇車禍判決皆會提及車禍 → 只用車禍去篩選會漏掉許多資料,例如第5, 6筆資料
- 非車禍案件也有很多提到車的可能 → 只用車去篩選也不宜,例如第3, 4 筆資料
- 車禍案件更常會同時提及撞 … 車 …,且兩字會在附近
1 | data = [..., |
上面的做法有以下兩個問題,也是為什麼我們希望使用正則要表達對字串的篩選邏輯
- 可讀性低
- 維護性低
- 使用正則的話
1 | import re |
什麼是正規表達式 Regular Expression
利用 文字 與一系列 定義好的符號 所組合而成的 規則模式(pattern),用來匹配我們的 目標字串。
車禍|車.{0,5}撞|撞.{0,5}車
搭配支援正則表達的工具、套件,對字串做 搜尋、替換 等處理。
該怎麼使用正則

RegExp 常見特殊符號
| 符號 | 解釋 |
|---|---|
. |
比對換行符\n以外所有字元 |
\w |
英文字母與數字 |
\s |
空白、換行符 \n、回車符 \rtab \t |
| |
代表 or,用於連結兩種 pattern |
| 符號 | 解釋 |
|---|---|
? |
0 或一次 |
+ |
連續出現一次以上 |
{x} |
x 次 |
{x,y} |
x~y 次 |
小練習
下列哪個正規表達式 無法 比對到 google?
g\s+gleg\w{1,}glego+gle
Python re 套件介紹
設定 pattern → 判斷字串中是否有這個 pattern → 我的 pattern 對應到的字是什麼
在 python 中,我們可以透過 re 這個套件執行正則表達式的操作
設定 pattern →
re.compile()1
2
3
4
5
6import re
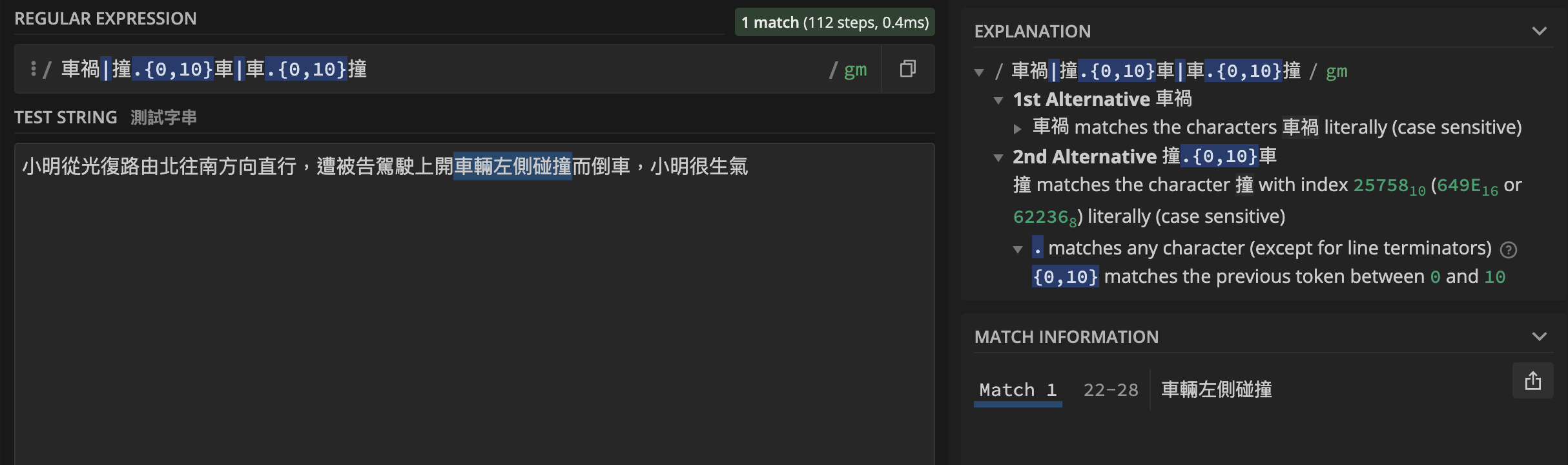
text = '小明從光復路由北往南方向直行,遭被告駕駛上開車輛左側碰撞而倒車,小明很生氣'
# 利用 re.compile 設定正規表達式
pattern = re.compile(r'車禍|撞.{0,10}車|車.{0,10}撞')字串是否符合我們要的 pattern →
re.search()1
2
3
4>>>re.search(pattern=pattern,
string=text)
# 在 index=22~28 match 到 ‘車輛左側碰撞’ 符合我們的規則
<re.Match object; span=(22, 28), match='車輛左側碰撞'>提取匹配到的字串 →
re.search().group()1
2>>>re.search(pattern, text).group()
'車輛左側碰撞'結合 pd.Series 找出符合規則的資料 →
pd.Series.str.contains()1
2
3
4
5
6
7
8
9
10>>>pattern = re.compile(r'車禍|撞.{0,10}車|車.{0,10}撞')
>>>data = pd.DataFrame({'text':
['小明從光復路由北往南方向直行,遭被告駕駛上開車輛左側碰撞而倒車,小明很生氣',
'abcdefghijklmnopgrstuvwxyz',
'甲乙丙丁戊']})
>>>data.text.str.contains(pat=pattern)
0 True
1 False
2 False想用 SQL 撈?→
RLIKE(適用HAP)1
2
3SELECT context
FROM the_table
WHERE context RLIKE '車禍|撞.{0,10}車|車.{0,10}撞'
工具分享
regex101: build, test, and debug regex
學習資源
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
Related Articles






Comment